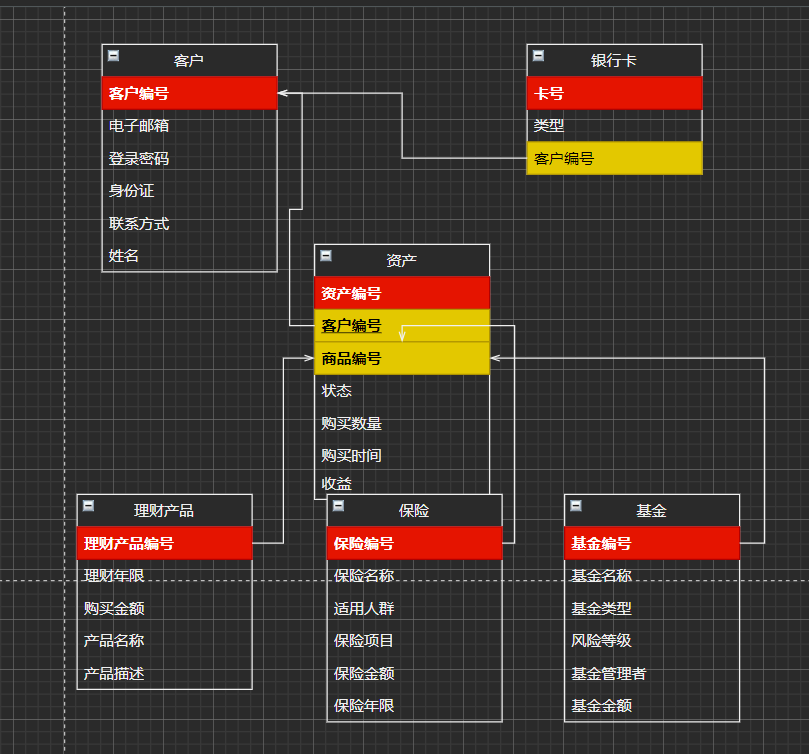
f_products表 ALTER table finance.f_products ADD CONSTRAINT c_p_mount CHECK (fp_amount >=0);
fund表
ALTER table finance.fund ADD CONSTRAINT c_f_mount CHECK (f_amount >=0);
insurance表 ALTER table finance.insurance ADD CONSTRAINT c_i_mount CHECK (i_amount >=0);
输出:
输出查询所有表的数据字典的查询语句和结果,可以截图或者复制黏贴代码。(基本都在之前有展示,这里对所有的表及schema进行了一次查询) select * from pg_tables;
输出查询所有表的数据的查询语句和结果,可以截图或者复制黏贴代码。
client表 select * from finance.client;
bank_card表 select * from finance.bank_card;
fund表 select * from finance.fund;
f_products表 select * from finance.f_products;
insurance表 select * from finance.insurance;
property表 select * from finance.property;
输出所有创建约束的语句和创建结果,可以截图或者复制黏贴代码(这在之前已经放上了)
对表中的数据进行查询操作
l 至少完成1条单表查询和1条表查询。(4分) 单表查询–查询客户表中所有的客户id
select c_id from finance.client;
表查询 select c_name from finance.client;
l 至少完成两条聚合查询,例如查询用户表中有多少个用户;查询保险信息表中,保险金额的平均值等。(4分) 查询property表的income平均值 select avg(p_income) from finance.property 查询用户表中用户总数 select count(*) from finance.client;
l 至少完成3条连接查询,例如:半连接、反连接、多表查询和子查询。(6分)
等值连接查询,查询每个用户及其拥有的资产 select finance.client.*,finance.property. * from finance.client,finance.property where finance.client.c_id=finance.property.p_c_id;
自身连接,在fund表中对每一个基金项,查询manager 和自身id相同的基金 select first.*,second.f_manager from finance.fund first,finance.fund second where first.f_id = second.f_manager
子查询,查询和p_id=3的资产处于相同状态的资产(然后发现就它自己冻结着) select * from finance.property where p_status= (select p_status from finance.property where p_id=3);
至少完成1条ORDER BY查询。(2分) 将资产按照收益逆序输出 select * from finance.property order by p_income desc;
至少完成1条GROUP BY……HAVING查询。(4分)
查询收益在2000及以上的资产及其平均收益,将结果按p_id分组显示,且只显示平均收益大于2500的组 select *,avg(p_income) from finance.property where p_income>=2000
group by p_id having avg(p_income)>=2500;
查询基金,将其按f_id分组,且只显示平均数量大于等于2000的组 select *,avg(f_amount) from finance.fund group by f_id having avg(f_amount)>=2000;
4.5 创建视图和索引
创建一个视图
查看client中属性,除了c_mail属性 create view see_client as select c_id,c_name,c_id_card,c_phone,c_password from finance.client
修改视图
修改视图所属schema alter view see_client set schema finance;
使用视图进行查询
重命名视图 alter view finance.see_client rename to oh_my_god;
删除视图
创建索引 为客户电话号码创建索引 CREATE INDEX index_phone on finance.client(c_phone) ;
重建索引 对整个客户表重建索引
重命名索引 alter index finance.index_phone rename to ind_phone;
删除索引
1.4.6 数据修改和删除(5分)
任务:
l 修改数据:至少修改2个不同的数据。(3分)
将client表中第1个元素的值c_name改为’年没怀念’ 之前的表 修改语句: update finance.client set c_name=’年没怀念’ where c_id=1;