1 | |
-M
Libnvdimm



1 | |


1 | |
1 | |
-M
Libnvdimm
1 | |
1 | |
从磁盘读数据的效率是从DRAM读数据的几乎10万倍慢,不过ssd会快的多,不过只是相对于传统磁盘而言
固态磁盘SSD
读SSD比写要快
SSD多次重复写后会损坏
计算机程序倾向于引用邻近与其他最近引用过的数据项的数据项
存储器地址位数: m
存储器地址数: M=2^m
高速缓存组数 S= 2^s
高速缓存组内缓存行: E
缓存行内数据块 B=2^b
高速缓存大小: C=S*E*B
特征: 每个组只有一行,因此字选择时简单,但容易发生抖动
流程: 假设执行一条读内存字w的指令
组选择:
- 从w中抽取s个组标记位,s由高速缓存组数决定
- 之后查看高速缓存中是否存在该组,如果存在就得到一个缓存命中,不存在就是缓存不命中
字选择:
- 高速缓存中的偏移位标识了字节在块中的偏移
行替换:
- 如果缓存不命中,就需要从层次结构的下一层中取出被请求的块,然后将心的块存储在组索引所示的块中
示例:
- 书P429
冲突不命中:
- 由直接映射的设计可以看出,如果程序访问大小为2的幂的数组,很可能会发生冲突不命中.
- 相同组映射的内存块会不断的来回覆盖–抖动
每个组都有 1<E<C/B 个高速缓存行的 的高速缓存通常称为E路组相联高速缓存
如果E=C/B 称为全相联高速缓存
行匹配
- 检查多个行的标记和有效位,判断是否在缓存中
行替换
- 如果组中有空行,则换到空行上去
- 如果没有,则根据替换策略替换–比如LRU
怎么更新层次结构中,低一层的副本
- 直写 – write throuth
- 立即将w的高速缓存块写回到紧接着的第一层
- 每次写都会引起总线流量
- 能够使用独立于高速缓存的写缓冲区用来更新内存
- 读不命中开销小
- 写回[ 延迟更新] write back
- 只有当替换算法要驱逐这个块时,将这个块写到低一层
- 显著减少总线流量
- 增加复杂性– 需要维护一个新的位[修改位]
- 允许更多到内存的贷款用于执行DMA的I/O.
如何处理写不命中
就是说,要写的块拿不到
- 写分配 write-allocate
- 加载相应的低一层的块到高速缓存中,然后更新这个高速缓存块
- 写回高速缓存通常是写分配的
- 非写分配 not-write-allocate
- 避开高速缓存,直接把这个字写到低一层中
- 直写高速缓存通常是非写分配的
编译器并不知道指针指向哪里,因此它必须假设指针可能指向同一个位置.
大多数编译器不会去判断一个函数是否有副作用,因此它们倾向于将函数的调用保持不变
内联
包含函数调用的代码可以用内联函数替换过程进行优化,就是将函数内部的执行步骤内联到一起
在gcc中,只尝试单文件的内联,不会尝试多文件的内联(比如一组函数在其他文件内的函数中被调用)
每元素的周期数
例如 :可以拿出来的拿出来
例: 如果一个循环中不断从结构体中的列表中获取值,而同时,结构体会不断对列表中值的存在进行判断
则可在保证安全的情况下,直接获取结构体中的列表进行访问.
例如
2
3
4
5
6
7
8
9
*dest=*dest+1;
}
// 将dest这个不断访问内存的东西挪到寄存器里
val tmp=*dest;
{
tmp=tmp+1;
}
*dest=tmp
延迟界限
当一系列操作必须按照严格顺序执行时会碰到
因为下一条指令开始前,这一条必须结束
代码中的数据相关限制了处理器利用指令级并行的能力时会碰到延迟界限
吞吐量界限
是处理器功能单元的原始计算能力,是程序性能的终极限制
- 比如n长的循环,2个一组展开之后,循环长度/2,这种称之为1*2循环展开
对一个n长的循环,进行k级别的展开,就需要将上限设置为n-k+1,这样最大循环索引会小于n
5.8.1 多个累积变量
例: 见书P370
上面的例子称之为2*2循环展开
5.8.2重新结合变换
该例子为2*1a循环展开
例
// slow version
acc= (acc * data[i]) * data[i+1]
//fast version
acc = acc * ( data[i] * data[i+1])
slow版里,每次计算都需要等之前的计算结果出来之后才能继续进行
fast版里,data[i]*& data[i+1]不受约束,因此可以被CPU并行优化,故效率高
书P378
当用到的临时变量过多,使得寄存器不够用的时候,会调用栈来存储这些变量,这会使得程序效率变低.
预测错误会导致较大的错误处罚,那么有什么办法来保证这个处罚对程序效率影响较小呢
不过分关心可预测的分支
例如,大部分结束循环的语句判断都是不结束,预测时一般都按照不结束来判断. 这时候只在最后一次会导致预测错误处罚.
书写适合使用条件传送实现的代码
最好使用条件数据传送而非条件控制转移.
数据传送示例:
max=a>b?a:b;
这种形式适合流水线并行操作.
- 高级设计: 为遇到的问题选择适当的算法和数据结构
- 基本编码原则. 避免限制优化的因素
- 消除连续的函数调用
- 在可能时,将计算一道循环外
- 消除不必要的内存引用
- 引入临时变量来保存中间结果,只有在最后的值计算出来时,才将结果存放到数组和全局变量中.
- 低级优化. 结构化代码以利用硬件性能
- 展开循环,降低开销
- 使用多个累计变量和重新结合技术,找到方法提高指令级并行
- 用功能性的风格重写条件操作,使编译采用条件数据传送.
CSAPP Machine Level Programming
数组的指针运算– 数组存储的是它的指针,其指针++ 会跳过存储数据量的位置(如 int a[10],a++ ,arr[a]会+4)
由于会根据struct中的最大的基本结构类型[int,double,float 之类的,和列表没关系]来进行对齐[例如,struct中存在double就会按照8byte对齐,如果最大只有int,就按照4byte对齐],因此,最好将结构合理组织,
如
2
3
4
5
6
7
8
9
10
char c;// 产生3个用于对齐的内存浪费
int i;
char d;// 产生3个用于对齐的浪费
}// waste 3+3 byte
struct S5{
int i;
char c;
char d;//c,d一并存储,产生2个用于对齐的浪费
}


- 注: 内存是按照0x7FFFFFFFFFFF 也就是2^47来作为地址的,所以各位置之间可能会有较大的差距[因为暂时,硬件条件并不会使得整块可供分配的内存id映射被用尽]
stack:
- 8MB
- 向下拓展[地址高标号低]
Data:
- 用于存放程序开始时分配的数据
- 存放全局变量
Heap:
- 存放通过malloc/相关函数申请的变量,会动态变化
- 大的数据块会出现在靠近stack的位置,并向下增长,小的数据块会出现在靠近Data的位置,并向上增长
SharedLibraries:
- 存放库函数代码[一般在磁盘上]
- 在运行时动态加载到内存中
举例: gets 会不断读取字符串,直至收到一个’\0’
2
3
4
5
6
{
char buf[4];/* Way too small*/
gets(buf);
puts(buf);
}此时,若输入大于4个字符,echo还是可以接收
查看汇编代码可以看到,调用echo的时候给stackFrame分配了24byte的空间
如果输入大于23个字符,就会报出 segment fault
- 这时候该函数的返回位置可能被溢出的字符串覆盖,使得函数不会到main这个接口,而是进入一个新的地区
- 这就是代码注入攻击
小于23就没事,
- 使用安全的替代
- fgets-> gets
- strncopy-> strcopy
- scanf(“%ns”)-> scanf(“%s”)
- Randomized stack offsets– 地址空间布局随机化
- 使得每次程序运行的时候,它分配到的缓冲区长度都是变化的
- None executable code segments
- 在可读/可写等内存标识之外增加一个 “execute” 权限
- stack canary 栈保护机制
- 程序会检测到栈溢出的问题并返回
- 但是躲不开canary
Gadget
A Example:
p后面的值恰好和mov rax rdi 相等,结尾又是一个c3,因此这一段额外的代码会在p赋值之后执行,并返回.
这样就实现了在代码中插入一定量的自己的小代码,返回后就可以通过获取rsp栈中的代码,来将之前的代码块拼接一起执行.
disass [FUNC_NAME]
解析对应函数的汇编代码
挑战来源: 基于 陷入-模拟 机制的虚拟化架构只能在所有敏感指令都是特权指令的架构中被建立
敏感指令: 操作敏感物理资源的指令,如I/O指令、页表基地址切换指令等
特权指令; 必须运行在最高特权级的指令,在非特权级中执行这些指令将会触发特权级切换。
解决方案:
软件方案: 解释执行【无脑解释执行所有指令,效率较低】,二进制翻译【将敏感指令替换为其他指令,会增加指令数量】,扫描与修补【在执行前,将敏感指令替换为特权指令,代码局部性较差】,半虚拟化【在执行敏感指令的时候通过超调用主动陷入Hypervisor中,避免扫描二进制代码引入的开销,但是打破了虚拟机和Hypervisor之间的界限】
硬件辅助方案: Intel VT-x,AMD SVM, ARM EL2, RISC-V H-Extension
将所有敏感指令转化为特权指令【可能存在兼容性问题】
引入虚拟化模式
类似进程上下文,虚拟机发生退出时需要保持各寄存器的状态
发生虚拟CPU调度时,需要保存当前虚拟CPU的上下文兵加载待调度虚拟CPU上下文
模拟方式:为每一个虚拟机维护一个虚拟中断控制器
每个控制器有几个寄存器,操作系统可以往里写东西
有些控制器上有,用于大数据传输
将位流组装为字节存入缓冲区中,形成字节为单位的块
cpu控制全过程
效率低下(CPU一直在等)
cpu发送指令,去干别的,等io设备准备好,利用中断通知cpu
cpu启动指令->DMA控制器->(data)->启动外设
整个数据的传输都是在DMA控制下进行的
cpu连接多个通道,通道连接多个控制器,再连接外部设备
imgtest
申请设备
将数据写入设备
从设备读取数据
释放设备
以一次IO为单位分时使用设备
利用磁盘上的输入输出并模拟高速外设
I.O交通管制程序
调度程序
设备处理程序
设备独立性–使软硬件相对独立,给上层软件更好的可移植性
设备统一命名-每种设备都是有名称的,如何命名以方便系统管理和用户使用是一个重要的问题
采取预先设计的,统一的逻辑名称
出错处理:数据尽可能在接近硬件层处理,仅当低层无能为力时,才将错误上交
缓冲技术:设法使数据的到达率和离去率匹配,提高系统的吞吐量
设备的分配:共享设备和独占设备的分配问题
支持文件所占存储介质空间的分配/回收
支持文件相对起始数据的逻辑块定位到外存上的物理块
支持对文件访问的安全检查
支持对文件的读写访问
用户看到的文件组织形式,和存储:设备无关
有结构的记录式文件:由一个以上的记录构成
无结构的流式文件:文件没有结构,由一串字符流构成
外存上存放形式,和存储设备特性有很大关系
•磁带
顺序访问设备→要求文件顺序存放于带上。
•磁盘
直接(随机)访问设备→文件可顺序、链接式或随机(通过类似页表的索引结构访问)存放于设备上
在用户逻辑文件和物理文件之间建立映射
读写文件存储器上的一个物理块的方法
顺序存取:指对文件中的信息按顺序依次读写
随机存取法:
**直接存取法:允许用户随意存取文件中任意一个物理记录**
**按键存取法:根据文件中各记录的某个数据项内容来存取记录的,这种数据项称之为键**
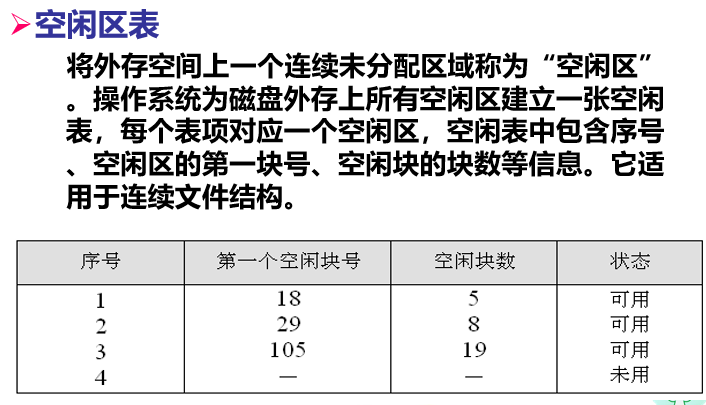
它将逻辑上连续的文件信息依次存放在编号连续的物理块上。
l优点:
–存储方式简单。
–对文件记录进行批量存取时,其存取效率较高。
–支持定长记录的直接存取,可以通过计算获得存储位置。
l缺点:
–不支持随机查找。如果要随机地查找或修改单个记录,此时系统需要逐个地查找诸记录,性能较差,尤其是当文件较大时情况将更为严重。
–存在外部碎片。
–不便于记录的增加或删除操作。
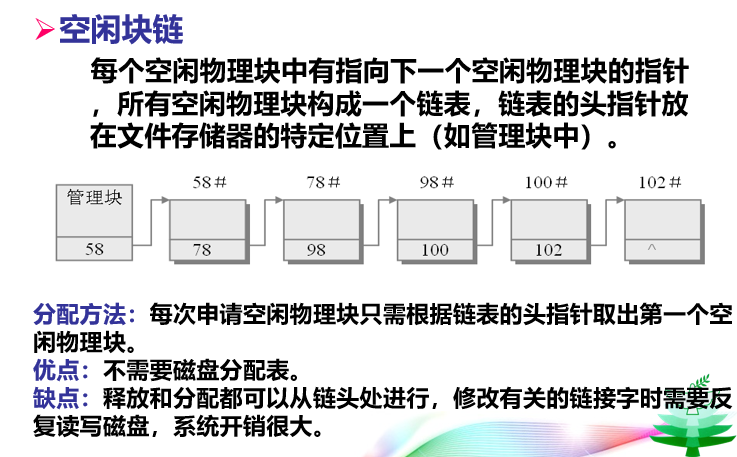
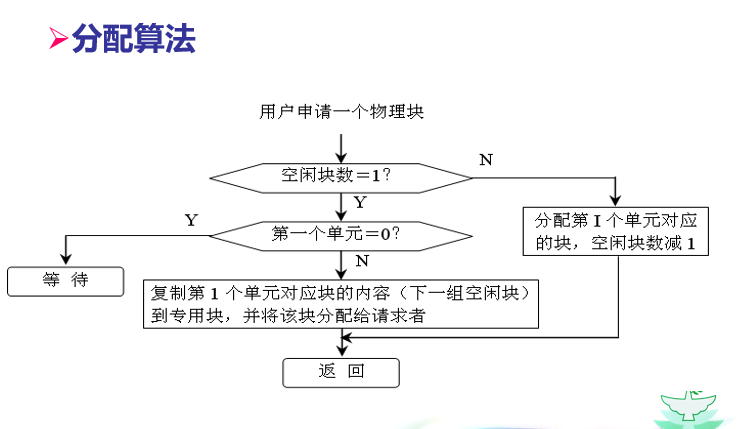
–链接结构
•将逻辑上连续的文件信息存放在不连续的物理块上,每个物理块设有一个指针指向下一个物理块。
l优点:
–提高了磁盘空间利用率,不存在外部碎片问题。
–有利于文件插入和删除,及其动态扩充。
l缺点:
–仍然不支持随机查找。
–由于存储空间可能不连续,带来更多的寻道次数和寻道时间。
–需要牺牲一些空间存放链接指针,同时需要维护这些指针,增加了系统开销。
–可靠性问题,如指针出错。
索引结构
将逻辑上连续的文件信息(记录)存放在不连续的物理块中,系统为每个文件建立一个专用数据结构——索引表,索引表中存放文件的逻辑块号和物理块号的对应关系
OS观点:文件包含文件控制块和文件体
文件控制块(FCB)的主要内容:
文件名
创建者
文件物理位置信息:如索引表
创建、修改时间、保存时间
口令:用于对文件访问进行验证
操作限制:如读、写、执行权限说明
文件目录提供的功能:
实现“按名存取”。用户只须提供文件名,即可对文件进行存取。这是文件系统向用户提供的最基本的服务。
提高对目录的检索速度。合理地组织目录结构,加快对目录的检索速度,从而加快对文件的存取速度。这是在设计一个大、中型文件系统时,所追求的主要目标。
实现文件共享。在多用户系统中,应允许多个用户共享一个文件,以节省大量的存储空间并方便用户。
解决文件重名问题。系统应允许不同用户对不同文件采用相同的名字,以便于用户按照自己的习惯命名和使用文件。
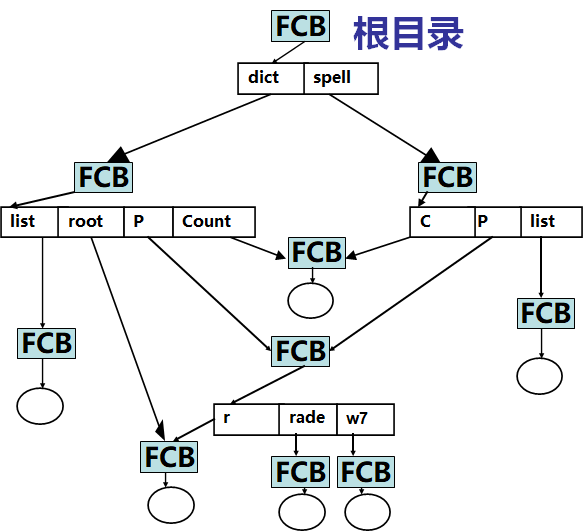
树状的多级目录结构
任何一级目录中的FCB既可以描述次一级的子目录,又可以描述一个文件
特点:
利于文件分类,从文件路径名可看出文件类别。
查找文件FCB耗费时间,要得到文件FCB,必须从根查起。
唯一确定文件的路径名太长,故引入当前目录 概念,提供相对于当前目录的相对路径名可加速文件FCB的查找,进程控制块存有当前目录信息
访问
必须指出文件所在路径名:从根目录到该文件的路径上各级目录名的组合。也称为文件全名。
例如:/usr/lib/man
相对路径:设置一个“当前目录”(也叫“工作目录”),此时对于文件的查找是从当前目录中进行的。可以带来两点好处:
用户使用更加方便
检索效率更高
优缺点
l树形多级目录结构的优点
•提高了检索目录的速度。
•较好地解决了重名问题。
l缺点
不便于用户共享文件
方便文件共享,分类。
两个或多个FCB的一致性难保证,因此将FCB独立存放,引入带文件/目录名和FCB指针的目录项